That’s Rotten
Predictive Models
Python
NLP
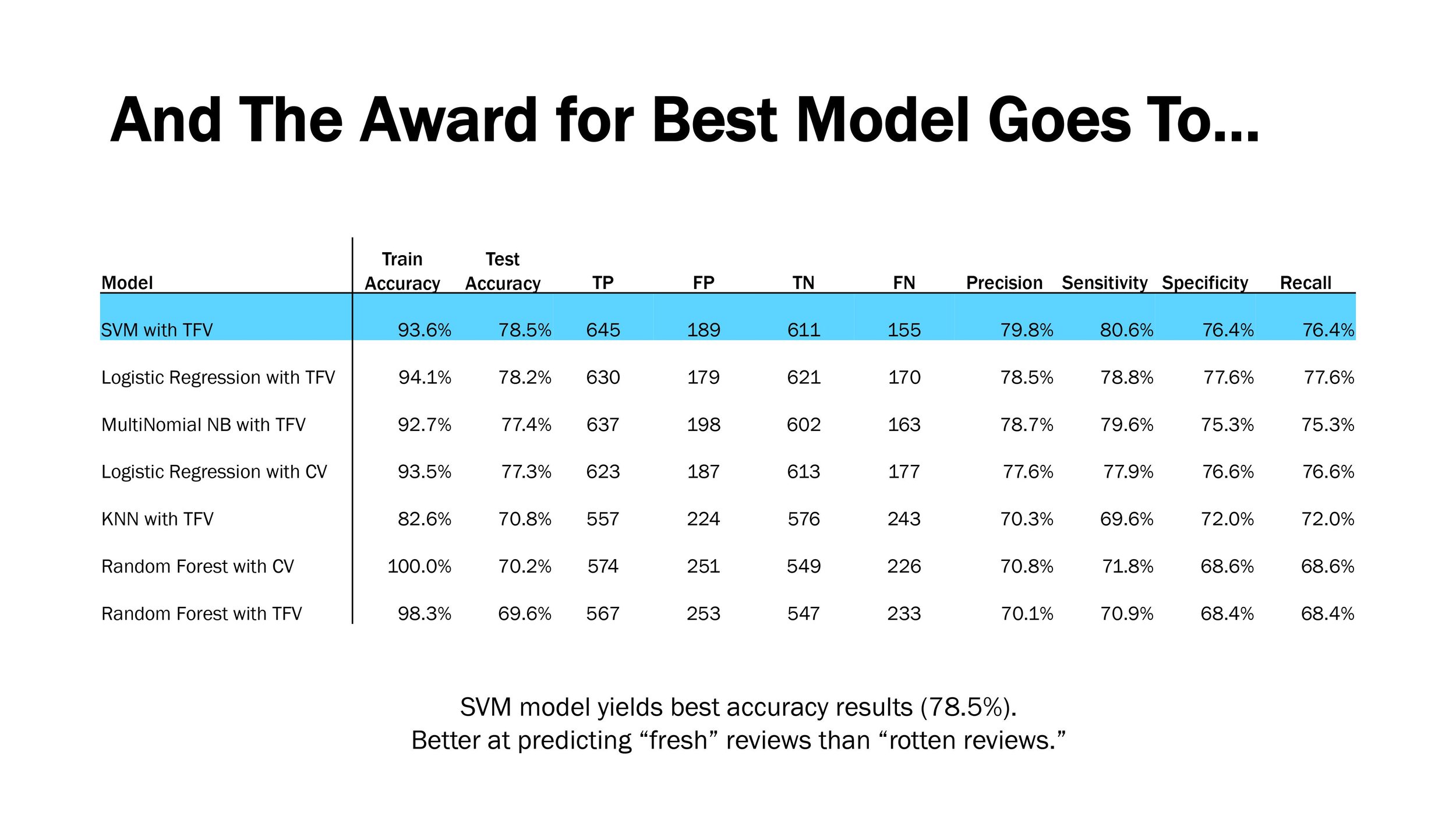
Can we use NLP to determine if the sentiment of a movie review is good or bad? Project uses data from Rotten Tomatoes to classify reviews using different classification models.
This project was part of a Data Science hackathon, participants had 7 hours to conduct EDA and build predictive models with a dataset of their choosing.
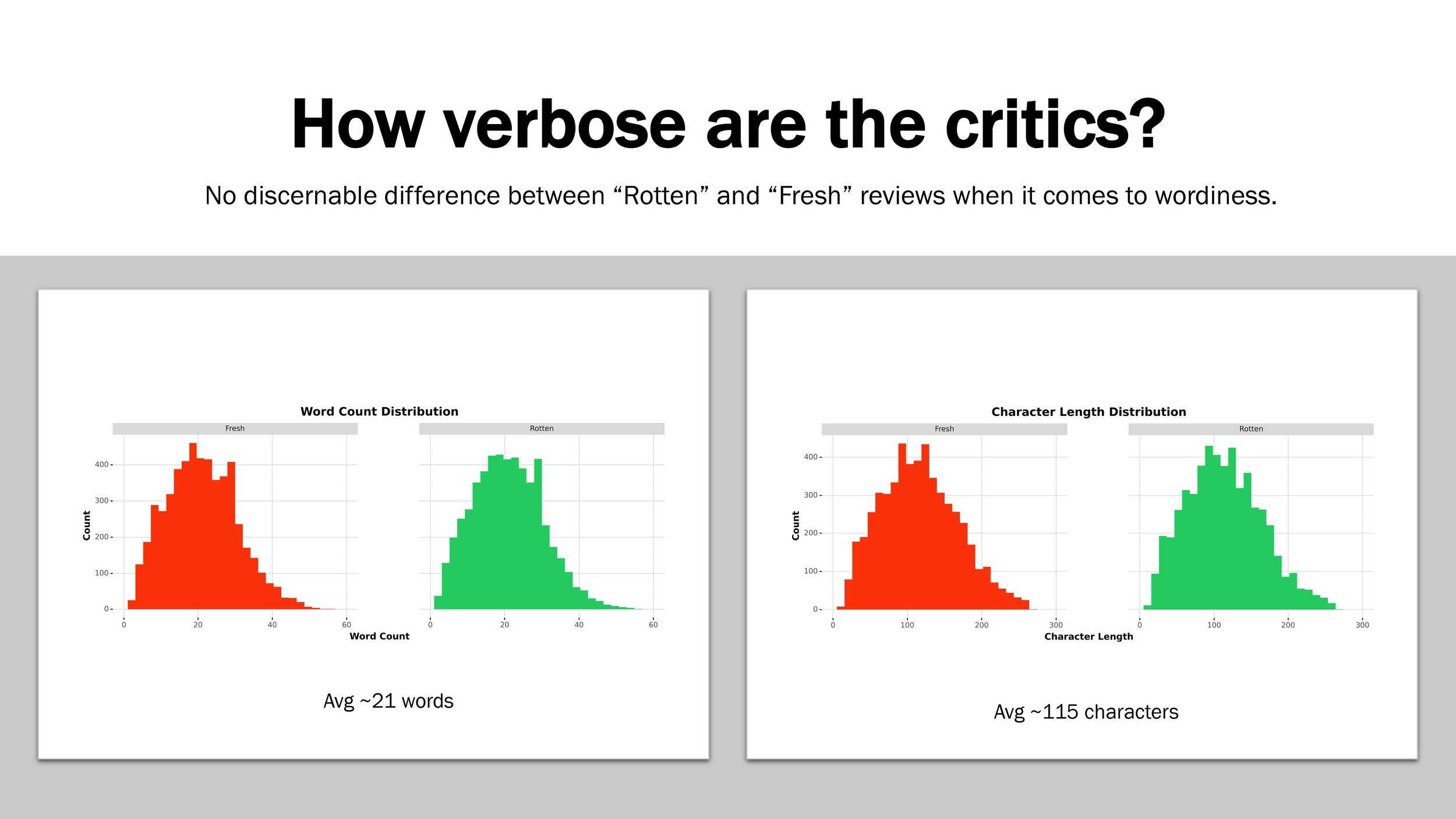
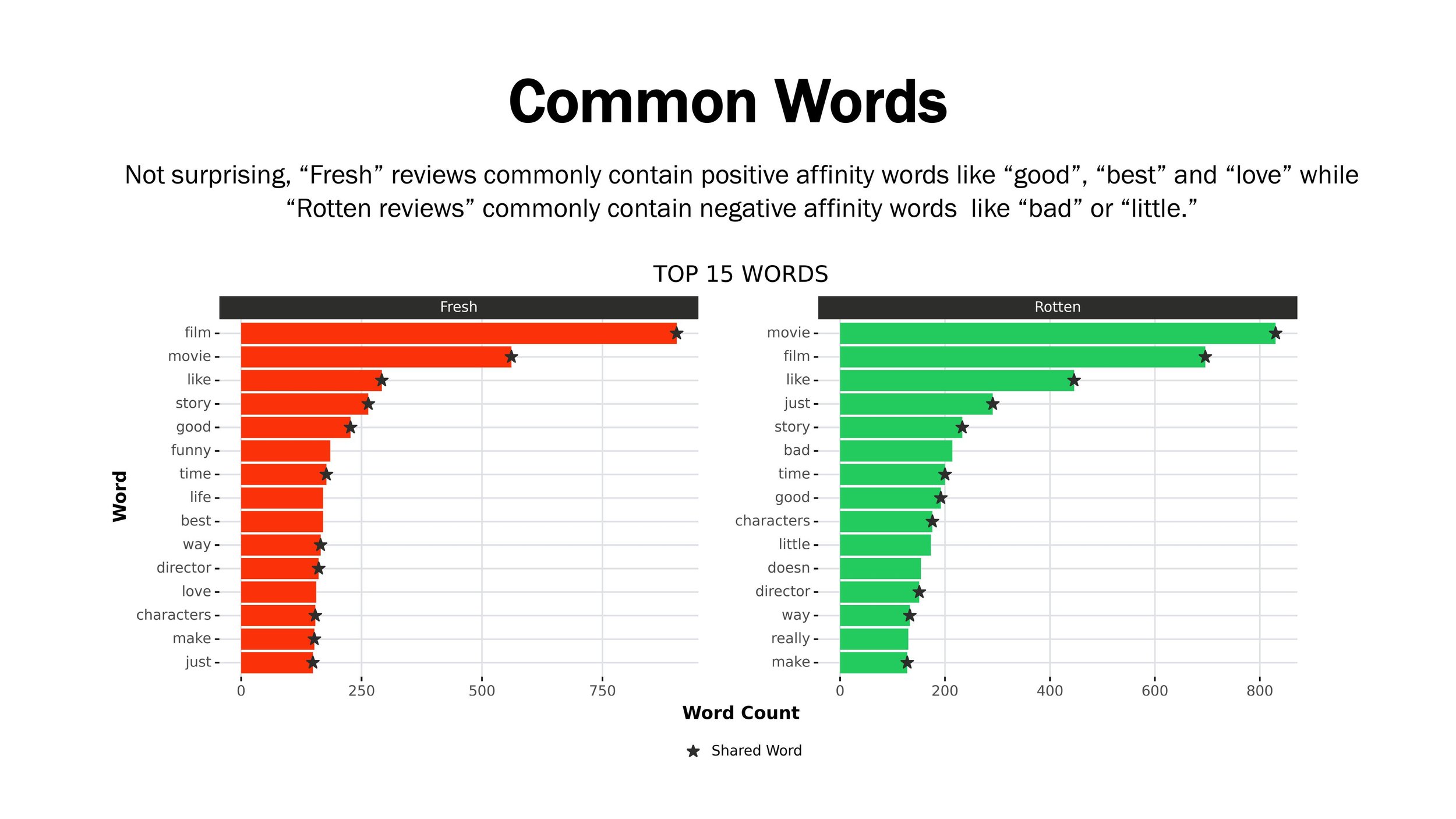
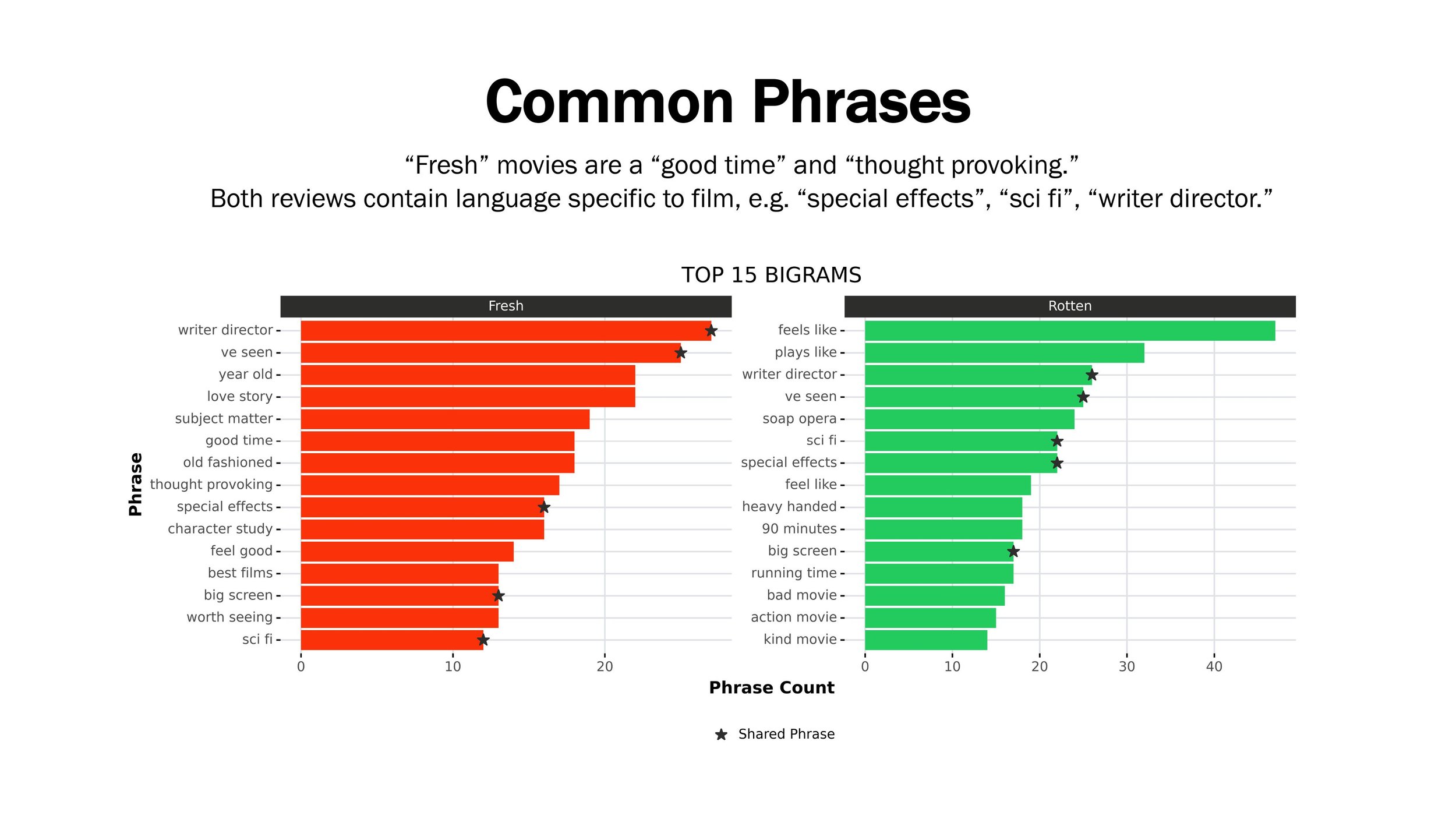
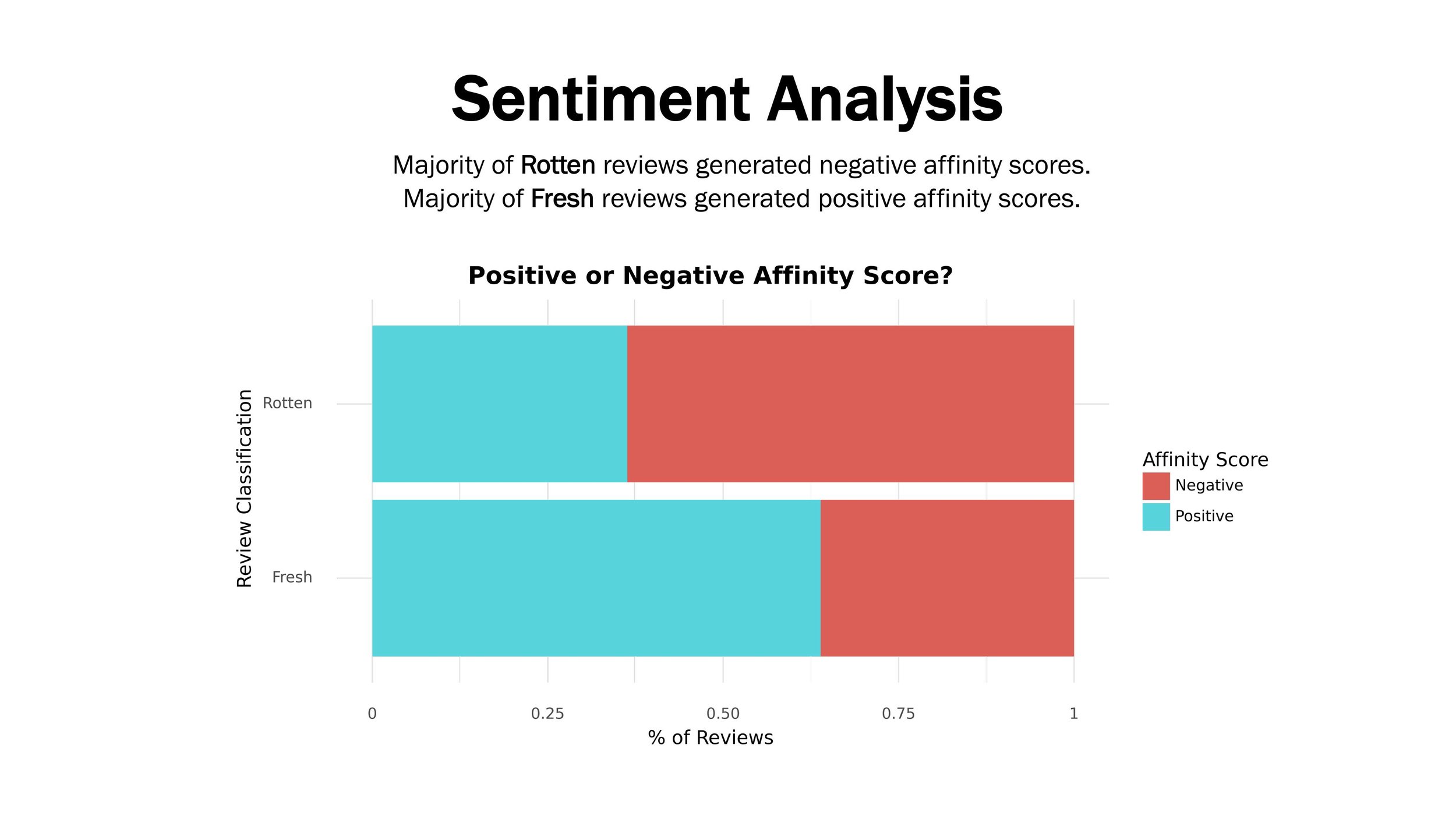
In this project, I focused on a dataset about Rotten Tomatoes movie reviews. The dataset was comprised of 10K+ text reviews and included classification labels (“Rotten”, “Fresh”).
My objective was to build a NLP classification model that could predict whether a review was “Rotten” and beat the baseline accuracy (50%).